Para entender y explotar los recursos de energía geotérmica, los datos y mapas geocientíficos son cruciales. Una de las tecnologías que permiten a los ingenieros crear mapas con las estructuras geológicas y los tipos de roca es el Geosteering: se interpretan las mediciones electromagnéticas adquiridas por un instrumento de registro de perforación equipado con transmisores y receptores y se cartografía la estructura geológica del subsuelo. La interpretación de los datos experimentales es, desde el punto de vista matemático, un problema inverso, que consiste en evaluar los parámetros específicos de una ecuación diferencial parcial a partir de unas mediciones dadas. Resolverla mediante métodos tradicionales es computacionalmente muy costoso.
Como parte del proyecto PIXIL, y en colaboración con el Barcelona Supercomputing Center, el equipo de BCAM pretende incorporar algoritmos de Deep Learning (DL) en la resolución de estos problemas. Los métodos de DL son rápidos, pero requieren un conjunto de datos de entrenamiento masivo. Esto es esencial para la estimación capa a capa de los modelos terrestres invertidos, que pueden ser utilizados para los ajustes en tiempo real de la trayectoria del pozo durante las operaciones de geonavegación.
En este contexto, hemos desarrollado recientemente una estrategia para generar bases de datos masivas que relacionan múltiples modelos de la Tierra con las correspondientes mediciones de resistividad del pozo. Para ello, discretizamos una formulación variacional 2,5D de las ecuaciones de Maxwell: utilizamos funciones de base polinómica y adoptamos el análisis isogeométrico refinado. Este mecanismo de refinamiento consiste en reducir la continuidad de la solución sobre zonas locales del dominio, manteniendo una distribución óptima de los recursos computacionales. Aunque esta estrategia aumenta el tamaño del problema, también rompe adecuadamente la rigidez de la matriz, lo que se traduce en una gran reducción con respecto a las discretizaciones isogeométricas tradicionales.
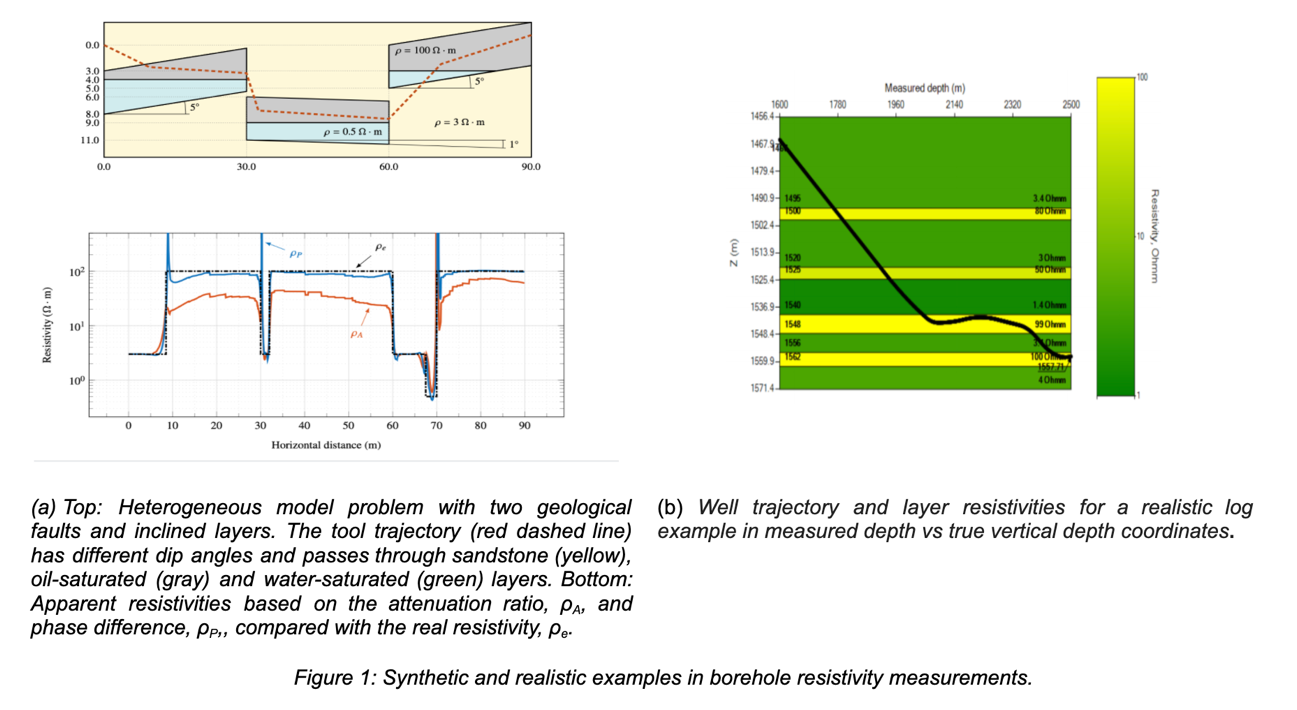
Para crear un conjunto de datos para la inversión de Deep Learning, primero seleccionamos ciertos parámetros de discretización basados en los resultados de varias soluciones homogéneas. A continuación, comprobamos la precisión en medios homogéneos y heterogéneos. En la Figura 1a, mostramos un problema de modelo heterogéneo con dos fallas geológicas y capas inclinadas (arriba), y las resistividades exactas y numéricas (abajo).
Finalmente, generamos una base de datos sintética significativa compuesta por 100.000 modelos de la Tierra con las mediciones correspondientes en unas 56 horas utilizando una estación de trabajo equipada con dos CPU. Con base de datos sintética significativa nos referimos a un conjunto de mediciones de pozos que cubren rangos adecuados de variación de las variables implicadas (es decir, los modelos de parametrización de la Tierra) y que deberían ser suficientes para una inversión robusta de DL. La figura 1b muestra la trayectoria del pozo y las resistividades de las capas para un ejemplo de registro realista en coordenadas de profundidad medida frente a la profundidad vertical real.
Las tareas futuras a desarrollar incluyen la consideración de modelos terrestres con múltiples fallas geológicas y la complementación de la base de datos sintética con modelos terrestres reales, junto con parametrizaciones más complejas del modelo terrestre que incluyan capas anisotrópicas.